Algorithm Techniques
For explanations of problems see Algorithm Problems.
For helpful reference, see Coding Cheat Sheet.
An algorithm is a well-defined computational procedure that takes in a set of values as inputs and produces a set of values as outputs. An algorithm is thus a sequence of computational steps that transform input into output.
Terminology
Nondecreasing order = an ordering where the next value is greater than or equal to the previous. Ex.
For values $x(n)$ and $x(n+1),\ x(n+1)>=x(n)$
Instance = an instance is a set of inputs to an algorithm that satisfy the input the input requirements.
Correct = an algorithm is said to be correct if, for every input instance, the computation halts when the correct output has been calculated.
Convex Hull = the smallest convex polygon that contains all points in a set of numbers that lie on a plane.
NP-complete problem = a problem for which there is currently no efficient algorithm that solves it, neither is there a proof that proves that the algorithm exists.
Proving an Algorithm
To prove an algorithm works, one way is by induction.
Start with the loop invariant, which is the subset of the input that is acted upon by the algorithm.
Then check for correctness in each of the following parts of the algorithm:
Initialization - Is it true prior to the first iteration of the loop?
Maintenance - Is it true at the start of the loop and also true at the end of the loop?
Termination - Is it true at the end of the loop?
Analysis
Analyzing an algorithm is predicting how much resources it will use. You have to model the implemented technology.
Input size - A measure of the input must be selected that has the most significant impact on the resources required for an operation. For instance in a multiplication algorithm the input size should be number of bits used in the input numbers.
Running time - This should be a machine independent number. Number of primitive steps executed.
Worst-case and average-case analysis
An algorithm's running time is dependent on the input data and there will be a best case, average case and worst case running time. The average case is often roughly as bad as the worst case. For instance with insertion sort.
Order of growth if the rate of growth of the running time. We consider the leading, most significant term of the formula of the worst case running time, called theta notation.
For an algorithm with a running time of $an^2 + bn + c$ the theta notation would be $Θ(n^2)$
Sorting Algorithms
Here's a breakdown of different sorting algorithms. There's sorting algorithms that sort in place, rely on element comparisons, others that don't.

Insertion Sort
For an unsorted list A of n length, loop through a growing subset of A by comparing the last element of the subset with each previous element and compare. If greater/smaller swap elements and iterate through again through a subset that is 1 larger than the previous.
1. for j = 1 to n 2. key = A[j] 3. i = j-1; 4. while i > 0 and key < A[i] 5. A[i+1] = A[i] 6. i-- 7. A[i+1] = key
Selection Sort
Find the smaller number and place it in A[1]. Then find smallest number in A[2..n] and place it in A[2]. Repeat
1. for i = 1 to A.length-1 2. //find the smallest number in A(i to n) 3. cur_smallest_index = i 4. for j = i+1 to A.length 5. if A[j] < A[cur_smallest_index] 6. cur_smallest_index = j 7. A[i] = temp 8. A[i] = A[cur_smallest)index] 9. A[cur_smallest_index] = temp;
Merge Sort
Merge sort is an O(n lg n) sorting algorithm that uses the dive and conquer paradigm.

Heaps
Heaps are implemented in C++ as priority_queue.
See this discussions.
Heaps allow us to put data into them and keep track of the mininum or maximum value. It does not ordered each individual element.
Heap Sort
Heap sort is an O(n lg n) sorting algorithm that sorts in place with a constant number of array elements stored outside the array at any time.
Heapsort uses a data structure called a “heap” to manage information.

A heap is a binary-tree that consists of a root, and parent nodes that have up to two child nodes. The math to retreive the the parent, left element or right element of a node is really simple.
Parent - $return\lfloor i/2 \rfloor$
Left - $return 2*i$
Right - $return 2*i+1$
There are two kinds of binary heaps, max-heaps and min-heaps. In both kinds the values in the nodes satisfy a heap property. In max-heap the max-heap property is that for every node $i$ other than the root,
$A[Parent(i)]\geq A[i]$
For min-heap the min-heap property is that for every node $i$ other than the root,
$A[Parent(i)]\leq A[i]$
There are a set of operation algorithms that are used in conjuction with heaps. They are as follows:
- Max-Heapify
- Build-Max-Heap
- Heapsort
- Max-Heap-Insert, Heap-Extract-Max, Heap-Increase-Key, Heap-Maximum
Max-Heapify
Runs in O(lg n), whose inputs are A and index i into the array. When it is called, Max-Heapify assumes that the binary trees rooted at Left(i) and Right(i) are max-heaps, but that A[i] might be smaller than its children. Max-Heapify lets the A[i] value “float” down so that the subtree rooted at index i obeys the max-heap property.
- Is index left smaller than A.heap-size and A[l] > A[i]?
- If yes, largest = l
- Else, largest = i
- Is index right smaller than A.heap-size and A[r] > A[i]?
- If yes, largest = r
- Else, largest = i
- If largest != i
- exchange A[i] with A[largest]
- Max-Heapify(A, largest)
Max-Heap-Insert
Runs in $O(lg\ n)$ time.
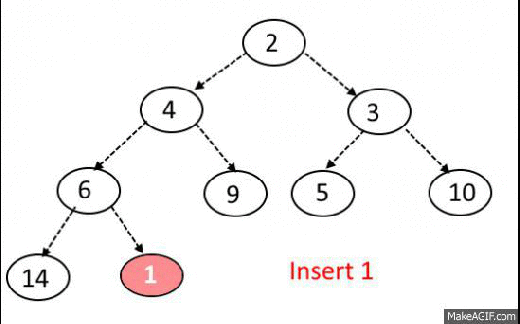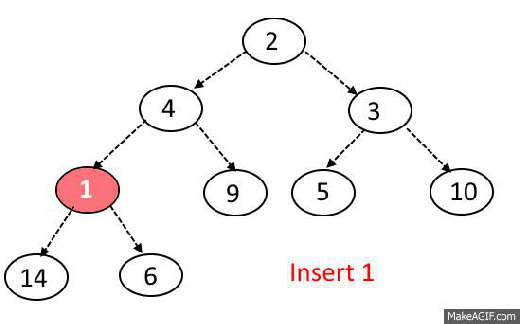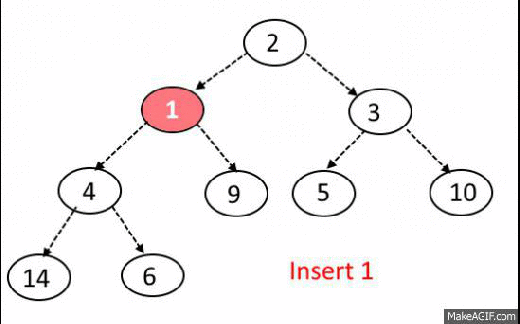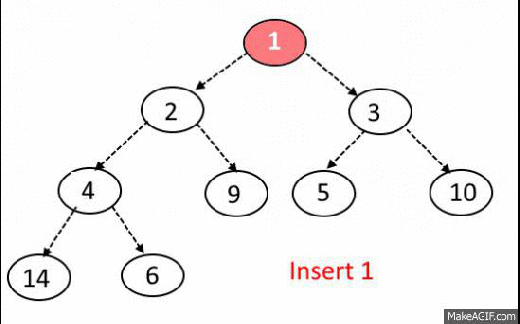
Max-Heap Insert. Input: heap array A, with data from 1 to length, element to insert p
// stuff the element at the end of the heap array
1. A[length+1] = p
// iterate up through the heap
2. int i = length + 1;
3. while i >= 0
// check if the parent node of our inserted element is less than it.
4. if (i/2 < p)
// swap the inserted element with its parent
5. A[i] = A[i/2]
6. A[i/2] = p
7. i = i/2
8. else
9. break
Build-Max-Heap
Build-Max-Heap uses Max-Heapify to a bottom-up manner to convert an array A[1..n], where n = A.length, in a max-heap. This procedure goes through the non-leaf nodes of the tree ($A[\lfloor n/2\rfloor..1]$) and runs Max-Heapify on each one.
Build-Max-Heap(A) 1. A.heap-size = A.length 2. for i = [A.length/2] down to 1 3. Max-Heapify(A,i)
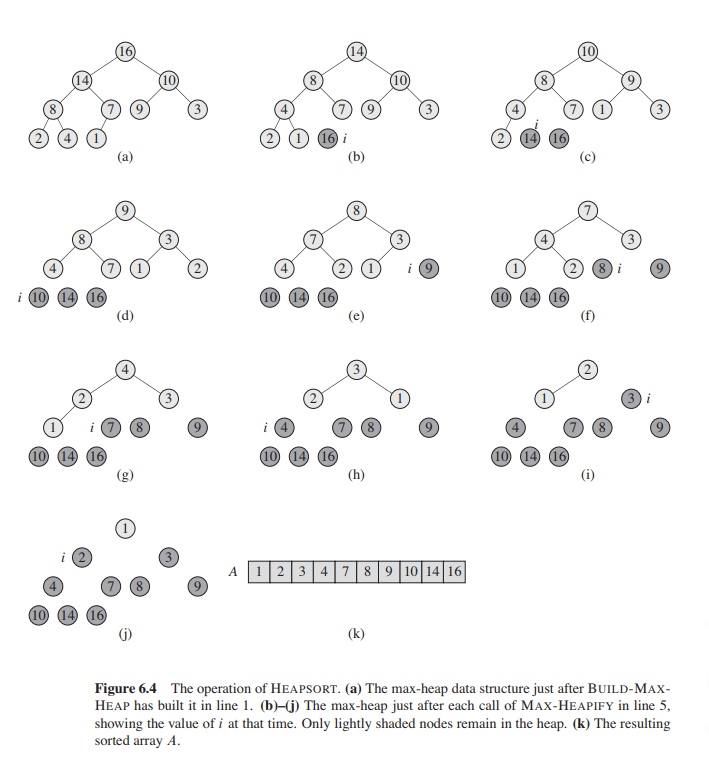
Heapsort
Heapsort works by building a max heap and then deconstructing it in order which in turn constructs a sorted array! Super neat and works in O(n lg n) time.
The algorithm works as follows:
Heapsort(A) 1. Build-Max-Heap(A) 2. for i = A.length down to 2 3. Exchange A[1] with A[i] 4. A.heap-length -- 5. Max-Heapify(A)
Quicksort
Quick sort selects a random location within the array called a pivot.
Then it creates two lists, one containing all elements smaller than the pivot, and one containing all elements greater than the pivot.
Then it recursively calls its with each of those two new lists. When the lists end up being only one element long, it all gets merged.

Priority Queue
Apparently heapsort is great and all, but quicksort beats it. What people do use is the heap data structure, with its most popular application being a priority queue. A priority queue is a data structure that contains a set of keys sorted by their priority. We use the following procedures when utilizing priority queues.
- Insert
- Find-Max
There are others that you can implement, but will make it difficult to address a element within the queue1).
- Delete-Max
- Change-Key
Divide and conquer
https://leetcode.com/explore/learn/card/recursion-ii/470/divide-and-conquer/2897/
Many algorithms are recursive, they call themselves recursively to deal with closely related sub-problems.
Divide - divide the problem into smaller subsets of the big set
Conquer - conquer the subproblems
Combine - combine the solutions to come up with the main solution of the bigger problem
A recurrence is an equation or inequality that describes a function in terms of its value of smaller inputs.
Methods for solving recurrences:
- substitution method guess a bound and then use mathematical induction to prove our guess correct
- recursion-tree method convert the recurrance into a tree whose nodes represent the costs incurred at various levels of the recursion.
- master method provides bounds for recurrences of the form $T(n) = aT(n/b) + f(n)$ where $a \geq 1,\ b\ > \ 1$ and $f(n)$ is a given function.

Binary Search Tree Validation
Validating a binary search tree can be solved with a divide and conquer approach. We check each node against an upper and lower bound. We then recurs and check both children.

Binary Trees
Binary trees. Height is log(n).
Bottom level of a perfect binary tree has roughly n/2 elements.
When traversing recursively, always thing of the following:
- What is my base case that I am checking for?
- What nodes will I call again recursively?


Iterative Postorder Traversal
You can accomplish a postorder traversal iteratively with two stacks. Here is the algorithm:
1. Put root in stack 1. 2. While Stack 1 isn't empty 3. pop top element of stack one and put it in stack 2 4. put the left and right child of that element in stack 1 5. Print contents of stack 2
Greedy Algorithms
A greedy algorithm is used to find optimal soltions - minimum or maximums. Problems are solved in stages, with each stage choosing the optimal solutions. If a solution is found, add it to your solutions.
n = 5
a = { a1, a2, a3, a4, a5 }
1. Algorithm Greedy(a,n) 2. for i=1 to n do: 3. x = Select(a) 4. if Feasible(x) Then: 5. Solution = Solution + x
Sliding Window
An approach for scanning through data is to use a sliding window technique.
For example, take this problem: find the length of the longest substring without repeating characters. Ex. Input: “abcabcbb” output = 3 (abc) and for “vadva” output = 3 (vadv)
To do this we have to scan through the input string while keeping track of the characters used. One such answer is as the following:
${\rm L{\small ONGEST}-S{\small UBSTRING}} (string)$
// our sliding window will be bound by i and j
1. int i = 0; j = 0; max = 0
// this is our hash table that contains a flag for every character
2. bool characterArray[128] = {false}
// iterate up starting from i = 0
3. for int j from 0 to < string.length
// if we've never seen this character before
// and tally our max and update our character hash key
4. if characterArray(string[j]) = false
5. max = (max > (j+1-i)) ? max : (j+1-i)
6. characterArray(string[j]] = true)
// if we have seen it before, reset it, and slide i forward one
// and try again
7. else
8. characterArray(string[i]] = false)
9. i++, j--
10. return max
Growth of Functions
Asymptotic efficiency is when we use an input size large enough to make only the growth of the running time relevant.
Θ-notation
Worst case running time of an algorithm.
$$Θ(g(n)) = \{f(n)\ :\ there\ exist\ positive\ constants\ c_1,\ c_2,\ and\ n_0\ such\ that\\\ 0 \le c_1*g(n)\le f(n) \le c_2*g(n)\ for\ all\ n\ \ge\ n_0\}$$
O-notation
O(g(n)) is defined as the set of functions which grow no faster than g(n).
$$0(g(n))\ =\ \{ f(n)\ :\ there\ exist\ positive\ constants\ c\ and\ n_0\ such\ that\\\ 0\leq f(n) \leq c*g(n)\ for\ all\ n\geq n_0\}.$$
or
$O(g(n))={f(n)\ :\exists\ c>0,\ n_0>0 \ni 0\leq f(n) \leq\ c*g(n) \forall n\geq n_0}$
Example2):

Using this example of $f(n)=5n$ and $g(n)=n$ we can prove that $O(g(n))=n$.
The definition of $O(g(n))$ is:
$f(n)\in O(g(n))\iff \exists c>0,n_0\ni \forall n \geq n_0,f(n)\leq c*g(n) $
Using this definition we can prove that $f(n)$ is a member of $O(g(n))$:
$n\in O(g(n)) \iff \exists c>0, 5n \leq c*n $
By substituting constant c = 6:
$n\in O(g(n)) \iff \exists 6>0, 5n \leq 6*n$
Ω-notation
Ω notation provides an asymptotic lower bound. For a given function $g(n)$, we denote by $Ω(g(n)$ (pronounced “big-omega of g of n” or “omega of g of n”) the set of functions
$$Ω(g(n))=\{f(n)\ :\ there\ exist\ positive\ constants\ c\ and\ n_0\ such\ that\\\ 0\leq c*g(n)\leq f(n)\ for\ all\ n\geq n_0\}$$.
o-notation
We use o-notation to denote an upper bound that is not asymptotically tight. We define $o(g(n))$ as the set:
$$o(g(n)) = \{f(n)\ :\ for\ any\ positive\ constant\ c>0,\ there\ exists\ a\ constant\\\ n_0>0\ such\ that\ 0\leq f(n)\ < c*g(n)\ for\ all\ n \geq n_0\}.$$
Difference Between O(log(n)) and O(nlog(n))
https://stackoverflow.com/questions/55876342/difference-between-ologn-and-onlogn/55876397
Think of it as O(n*log(n)), i.e. “doing log(n) work n times”. For example, searching for an element in a sorted list of length n is O(log(n)). Searching for the element in n different sorted lists, each of length n is O(n*log(n)).
Remember that O(n) is defined relative to some real quantity n. This might be the size of a list, or the number of different elements in a collection. Therefore, every variable that appears inside O(…) represents something interacting to increase the runtime. O(n*m) could be written O(n_1 + n_2 + … + n_m) and represent the same thing: “doing n, m times”.
Let's take a concrete example of this, mergesort. For n input elements: On the very last iteration of our sort, we have two halves of the input, each half size n/2, and each half is sorted. All we have to do is merge them together, which takes n operations. On the next-to-last iteration, we have twice as many pieces (4) each of size n/4. For each of our two pairs of size n/4, we merge the pair together, which takes n/2 operations for a pair (one for each element in the pair, just like before), i.e. n operations for the two pairs.
From here, we can extrapolate that every level of our mergesort takes n operations to merge. The big-O complexity is therefore n times the number of levels. On the last level, the size of the chunks we're merging is n/2. Before that, it's n/4, before that n/8, etc. all the way to size 1. How many times must you divide n by 2 to get 1? log(n). So we have log(n) levels. Therefore, our total runtime is O(n (work per level) * log(n) (number of levels)), n work.
Backtracking
Backtracking is an algorithm that looks at all possible solutions for a problem and evaluates each one.
Prefix Sum
Intervals
To check if intervals overlap simply do this!
min
end
|---------->
|------------>
max
strt
|------------>
|---->
max min
strt end
|------------>
|----> max
min strt
end
if(MININUM_END_TIME > MAXIMUM_START_TIME) WE OVERLAP!
Graphs
Graphs are a great way of storing the way data depends on data.
Types of Graphs
Undirected Graphs and Directed Graphs
Undirected Graphs don't have edges to them. You can go from A to B or B to A. No problems!

Directed Acyclical Graphs (DAGS)

These graphs don't have any cycles, so you can you explore the whole connected graph without entering a loop.
Adjacency Lists
Graphs can be represented by Adjacency Matrices, and Adjacency lists. Adjacency
Matrices are rarely used because they take up V² space. Adjacency Matrices
are 2D boolean arrays that specify if a vertex I is connected to vertex J.

Adjacency lists Representing a graph with adjacency lists combines adjacency matrices with edge lists. For each vertex iii, store an array of the vertices adjacent to it. We typically have an array of |V| adjacency lists, one adjacency list per vertex. Here's an adjacency-list representation of the social network graph:

In code, we represent these adjacency lists with a vector of vector of ints:
[ [1, 6, 8], [0, 4, 6, 9], [4, 6], [4, 5, 8], [1, 2, 3, 5, 9], [3, 4], [0, 1, 2], [8, 9], [0, 3, 7], [1, 4, 7] ]
Graph Edges
A Back Edge is an edge that connects a vertex to a vertex that is discovered before it's parent.
Think about it like this: When you apply a DFS on a graph you fix some path that the algorithm chooses. Now in the given case: 0→1→2→3→4. As in the article mentioned, the source graph contains the edges 4-2 and 3-1. When the DFS reaches 3 it could choose 1 but 1 is already in your path so it is a back edge and therefore, as mentioned in the source, a possible alternative path.
Are 2-1, 3-2, and 4-3 back edges too? For a different path they can be. Suppose your DFS chooses 0→1→3→2→4 then 2-1 and 4-3 are back edges.

Graph Traversal
You can traverse a Graph in two ways, Depth First Traversal and Breath First Traversal.
Depth First Traversal
As the name implies, Depth First Traversal, or Depth First Search traversal, involves going all the way down to vertex that has no other possible unexplored vertices connected to it, and then backtracking to a previous node.
The best analogy for this is leaving breadcrumbs while exploring a maze. If you encounter your breadcrumbs, turn back to the next closes turn, and turn into an explored area. Thanks to Erik Demaine for this analogy.

DFT is accomplished with a Stack.
The basic algorithm:
1. Push first vertex onto the stack. 2. Mark first vertex as visited. 3. Repeat while Stack is not empty 4. Visit next vertex adjacent to the one on top of the stack 5. Push this vertex on the stack 6. Mark this vertex as visited 7. If there isn't a vertex to visit 8. pop vertex off top of the stack
For Directed Graphs or graphs that contain disconnected graphs, we need an extra step to make sure we visit all vertices in the graph.


V is a set of vertices in our graph. Adj is the adjacency list.

Breath First Traversal

BFT is accomplished with a Queue.
1. Push first vertex into queue 2. Mark first vertex as seen 3. While queue not empty 4. Pop front of the queue. 5. Visit all neighboring verticles 6. If they are not seen 7. Push them onto the queue.
Permutations and Combinations
Theres like… all these different kinds of permutations and combinations with repetitions, with unique values, etc.
Unique permutations with unique result
- Sort input candidates.
- Make a boolean flag array to track used elements.
- Recurse over the candidates, choosing and building a solution, and then unchoosing.
- If the next option is the same, skip it.